The first part of this project straddles a variety of topic areas including:
- Natural Language Processing (NLP)
- Bidirectional Encoder Representations from Transformers (BERT)
- Sentiment Analysis
Introduction and Problem Statement
According to seedscientific.com, Facebook generates over 4 petabytes of data every day, Snapchat generates over 200,000,000 snaps, and Twitter generates over 500,000,000 tweets. Much of this is text data. Can we extract anything useful and understand what people are saying on such a grand scale? Aspect Based Sentiment Analysis (ABSA) attempts to help us do just this. In this project we will make a first pass attempt at our own scaled down version of Aspect Based Sentiment Analysis by combining a BERT based sentiment classifier with a topic modeling algorithm known as Latent Dirichlet Allocation (LDA).
In this first part, I’ll train three BERT sentiment classifiers on the IMDB Dataset available from Stanford, changing up the training process just slightly each time. Then, I’ll process my own corpus of 1,338 scouting reports for NHL draft eligible players into a form readable by these BERT classifiers and get them to predict sentence-by-sentence sentiment for each report. Taking a random sample of text from my corpus, I’ll attempt to estimate the accuracy of these sentiment predictions and finish with a discussion of what works well and what could be improved upon.
In part II of this series, I’ll prepare the same raw text in a very different manner, construct an LDA model for topic modeling purposes, and then use this model to understand what each sentence is likely about. Finally, I’ll combine sentiment scores with Topic predictions and examine whether our combined models can really tell us what sentences are about and what their directional sentiment is.
If you would prefer to preview the actual results of this project rather than follow along step by step, here is my wrap-up video for the project. In this video I look at individual sentences which were assigned to the same categories and given sentiment scores:
Data Description & Preprocessing
As a subscriber to ESPN+, The Athletic, and FCHockey, I’ve been able to create a corpus of written scouting reports for NHL draft eligible players, which is what I use as the basis of this project. Due to copyright protection issues, I can’t publicly share the corpus I’m using here, but I will show a snippet of the dataframe.

In all, we’re working with 1,338 reports, ranging in word counts from roughly 60-300. I’ve taken the pre-emptive step of removing the the words ‘offense,’ ‘offensive,’ and ‘offensively,’ and replacing them with a placeholder token (in this case, ‘ooohhhh’ is that placeholder). This was done for the sake of making sentiment analysis possible. As it turns out, statements like “He’s the most offensive player in the draft,” are a real challenge for pre-trained sentiment models.
Because none of my own data is labeled, I’ve chosen to train the model on the Stanford IMDB dataset, which contains 25,000 movie reviews, most of which come with strict positive or negative labels.
The first part of the video series for this project is below:
Working with BERT
There are several resources out there for working with BERT in sentiment analysis. The most straight forward approach I’ve found comes from a towardsdatascience.com article, which you can find here. In that article, the author shares the exact code necessary for fine tuning a BERT model for Sentiment analysis using the Stanford IMDB dataset discussed above. Although there are more sophisticated things we can do, this is a quick and easy way to get started on a first pass attempt. Following the approach laid out there, I was able to construct three separate BERT sentiment classifiers. By changing up the training process slightly each time, I ended up with three slightly different models to use as an ensemble.
Finally some of my own code to talk about here. Using the loop shown below, we can get our individual models to make sentiment predictions and then store these in dataframes. Please note that the code below functions only if the original work depicted in the towardsdatascience.com article I linked to above has already been run.
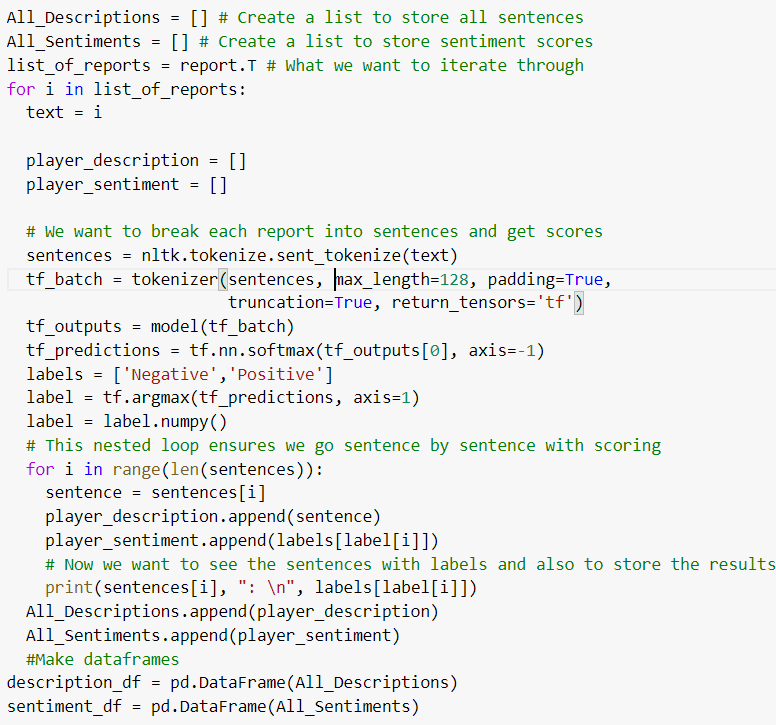
What we get out of this loop is a printout of each sentence with its corresponding sentiment prediction, as well as two dataframes – one with individual sentences, which looks like this:
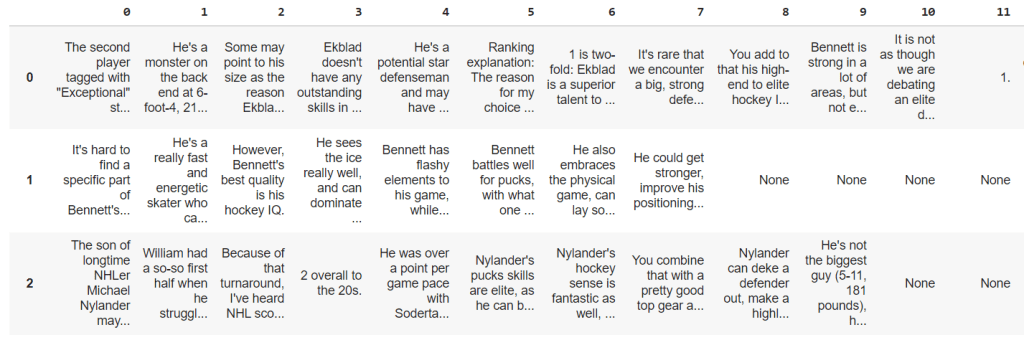
And one with the sentiment predictions, which looks like this:
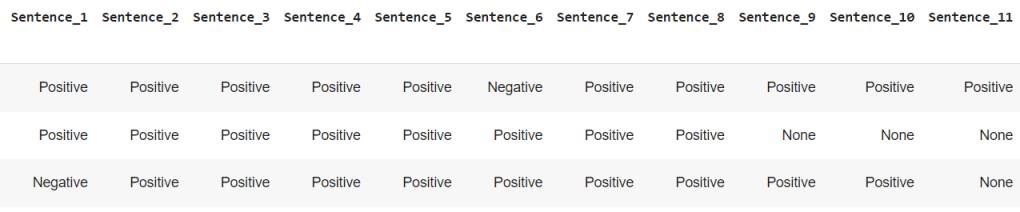
The last issue to overcome here is the fact that not all reports have the same number of sentences. This gives us the “none” spaces in our dataframes depicted above. We can fix easily.


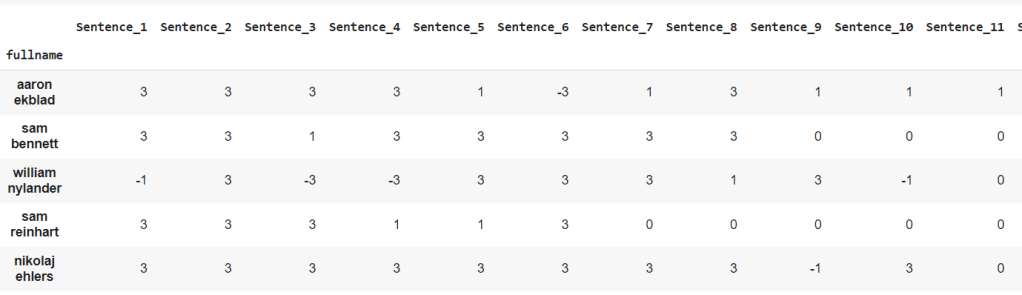
Finally, by changing all sentiment labels to numbers (1, 0, -1, for positive, neutral and negative respectively), we can combine predictions. This is simple enough to accomplish, we just need to use df.replace( ) and then add all three together. The end result looks like this:
Results & Discussion
Results on a grand scale are difficult to assess because our scouting report data didn’t come with labels. However, after taking a sample of 143 sentences and applying my own subjective judgement, I would say our classifier is only about 85-88% accurate using a weighted score. It has a particularly tough time recognizing the negative class, which in my sample only showed about 60% recall. However, this is okay for a first pass attempt and can be improved upon in future iterations.

Digging into individual reports is more illuminating than looking at scores in the aggregate, however. Here is one full report broken out by sentence with all three sentiment predictions shown.
| Sentence | BERT 1 | BERT 2 | BERT 3 | Total |
| Cernak has also been a very impressive prospect for some time, being one of Slovakia’s top under-18 products of the past 10-15 years. | Positive | Positive | Positive | +3 |
| He has a ton of high-level experience, including a great season in Slovakia’s top league and playing for the national squad. | Positive | Positive | Positive | +3 |
| His tool kit is extremely appealing, and he has a raw upside that’s sky high: He projects to skate and handle the puck at above-average NHL levels. | Positive | Positive | Positive | +3 |
| Cernak is also a physical defender who can make defensive stops as well as play a part on a team’s power play. | Positive | Positive | Positive | +3 |
| His main issue is his hockey IQ, as he shows a moderate frequency to make bad decisions on hits, pinches and puck decisions. | Negative | Negative | Negative | -3 |
| At the top of his game, he can look like a dominant two-way defenseman, but that is not always the guy who shows up. | Positive | Positive | Negative | +1 |
Corey Pronman, “Top 100 Prospects for the 2015 NHL Draft.”
The first five sentences here present no issue to our ensemble. All three classifiers agree as to the classification. The sixth sentence contains both positive and negative sentiment however, which complicates the issue. Here we have two models saying it’s positive, and one saying it’s negative.
Using my subjective human judgement, I labeled that last sentence as overall negative, meaning that the ensemble model technically got the prediction wrong. However, there is a good argument to be made that this ensemble model is correctly identifying the ambiguity present in that sentence. In some ways, the ensemble is recognizing a third class aside from the strictly positive and negative classes we originally sought out. The fact that every other sentence has a clear positive or negative sentiment, but that last sentence produces disagreement within our ensemble model is an encouraging sign.
What Comes Next
Now that we have our ensemble model predictions for sentiment at the sentence level, the next step is to leverage LDA for the purpose of topic modeling. By looking for co-occurrence patterns in our scouting report data, the LDA algorithm will help us identify topics and certain aspects of player evaluation. I’ll talk more about this in part II of the project, but for now it is useful to know that the use of LDA at the sentence level is somewhat unorthodox. We will discuss why that is the case (and why I think an exception is warranted here) next time.
Click here for Part II of this Project.
